Koans는 불교에서 유래된 단어로, 결론을 내리기 전에 이게 왜 맞는지 깊게 고민한다는 의미를 가지고 있다고 한다. 답이 미리 제시되어 있기 때문에 고민 없이 풀면, 큰 어려움 없이 전부 다 풀 수 있지만 그게 왜 정답인지 깊게 고민해 보는 시간을 갖지 않는다면 충분히 성장하기 어려울 것이다. 즉, '왜?' 라는 물음에 대해 꼭 깊은 고찰을 하고 넘어가자는 의미이다.
원시 자료형(primitive data type 또는 원시값)
- 객체가 아니면서 method를 가지지 않는 아래 7가지의 데이터 (궁금)
- string, number, bigint, boolean, undefined, symbol, (null)
ㄴ method를 가지지 않는다?
원시값은 객체는 아니지만, 객체에서 하는 것처럼 메서드를 호출할 수 있다.
- 원시값을 다룰 때, 메서드를 사용하면 작업이 수월할 것 같지만 원시값은 최대한 빠르고 가벼워야 한다.
- string, number, boolean, symbol의 메서드와 프로퍼티에 접근할 수 있도록 언어 차원에서 허용한다.
- 즉, 원시값이 메서드나 프로퍼티에 접근하기 위해 "원시 래퍼 객체(object wrapper)"라는 특수한 객체를 만들어주고, 접근 후에는 객체는 삭제된다.
- 각 래퍼 객체는 원시 자료형의 이름과 비슷하지만 앞을 대문자로 만든다. (String, Number, Boolean, Symbol)
- 참고 사이트
bigInt란?
- BigInt 는 Number 원시 값이 안정적으로 나타낼 수 있는 최대치인 2^53 - 1보다 큰 정수를 표현할 수 있는 내장 객체 이다.
- BigInt는 정수 리터럴의 뒤에 n을 붙이거나(10n) 함수 BigInt()를 호출해 생성할 수 있다.
- BigInt는 내장 Math 객체의 메서드와 함께 사용할 수 없고, 연산에서 Number와 혼합해 사용할 수 없다. (먼저 같은 자료형으로 변환해야 하지만 BigInt가 Number로 바뀌면 정확성을 잃을 수 있으니 주의해야 함)
const theBiggestInt = 9007199254740991n;
const alsoHuge = BigInt(9007199254740991);
// ↪ 9007199254740991n
const hugeString = BigInt("9007199254740991");
// ↪ 9007199254740991n
const hugeHex = BigInt("0x1fffffffffffff");
// ↪ 9007199254740991n
const hugeBin = BigInt("0b11111111111111111111111111111111111111111111111111111");
// ↪ 9007199254740991n
describe('primitive data type과 reference data type에 대해서 학습합니다.', function () {
it('원시 자료형은 값 자체에 대한 변경이 불가능(immutable)합니다.', function () {
let name = 'codestates';
expect(name).to.equal('codestates');
expect(name.toUpperCase()).to.equal("CODESTATES");
expect(name).to.equal(`codestates`);
// 새로운 값으로 재할당은 가능하다.
name = name.toUpperCase();
expect(name).to.equal("CODESTATES");
/*
원시 자료형은 값 자체에 대한 변경이 불가능하다고 하는데, 한 변수에 다른 값을 할당하는 것은 변경이 된 것이 아닌가?
let num1 = 123;
num1 = 123456;
원시 자료형 그 자체('hello', 123, 123456, 456n, true 등)와 원시 자료형이 할당된 변수는 구분되어야 한다.
*/
});
it('원시 자료형을 변수에 할당할 경우, 값 자체의 복사가 일어납니다.', function () {
let overTwenty = true;
let allowedToDrink = overTwenty;
overTwenty = false;
expect(overTwenty).to.equal(false);
expect(allowedToDrink).to.equal(true);
let variable = 'variable';
let variableCopy = 'variableCopy';
variableCopy = variable;
variable = variableCopy;
expect(variable).to.equal('variable');
});
it('원시 자료형 또는 원시 자료형의 데이터를 함수의 전달인자로 전달할 경우, 값 자체의 복사가 일어납니다.', function () {
let currentYear = 2020;
function afterTenYears(year) {
year = year + 10;
}
afterTenYears(currentYear);
expect(currentYear).to.equal(2020);
function afterTenYears2(currentYear) {
currentYear = currentYear + 10;
return currentYear;
}
let after10 = afterTenYears2(currentYear);
expect(currentYear).to.equal(2020); // **
expect(after10).to.equal(2030);
// 사실 함수의 전달인자도 변수에 자료(data)를 할당하는 것으로 전달인자의 값은 단순히 기존값이 복제된 값이다.
// 함수를 호출하면서 넘긴 전달인자가 호출된 함수의 지역변수로 (매 호출 시마다) 새롭게 선언된다. ****
});
다른 경우들을 콘솔로 찍어봤다.
매개변수가 year일 때
1) var 키워드 사용
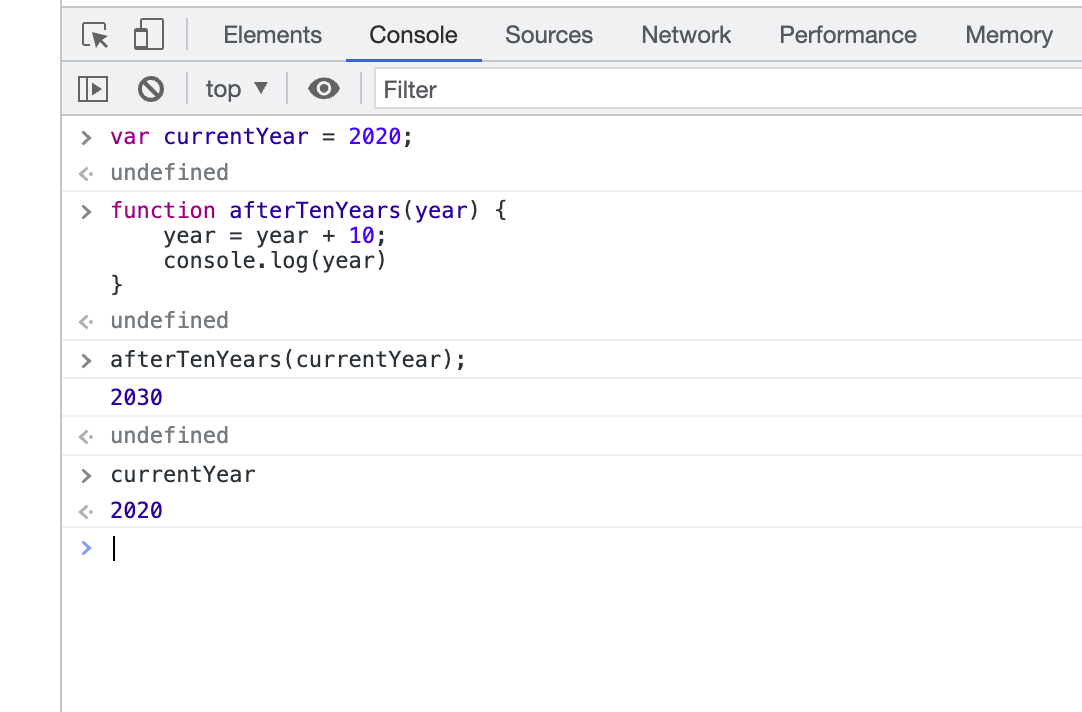
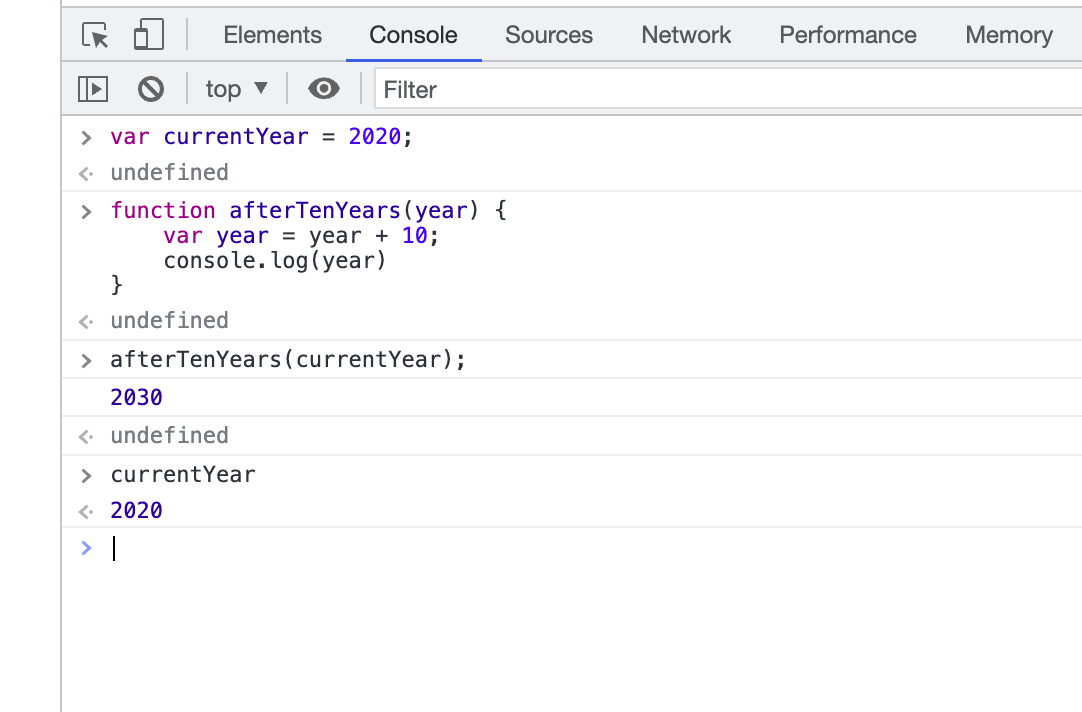
2) let 키워드 사용

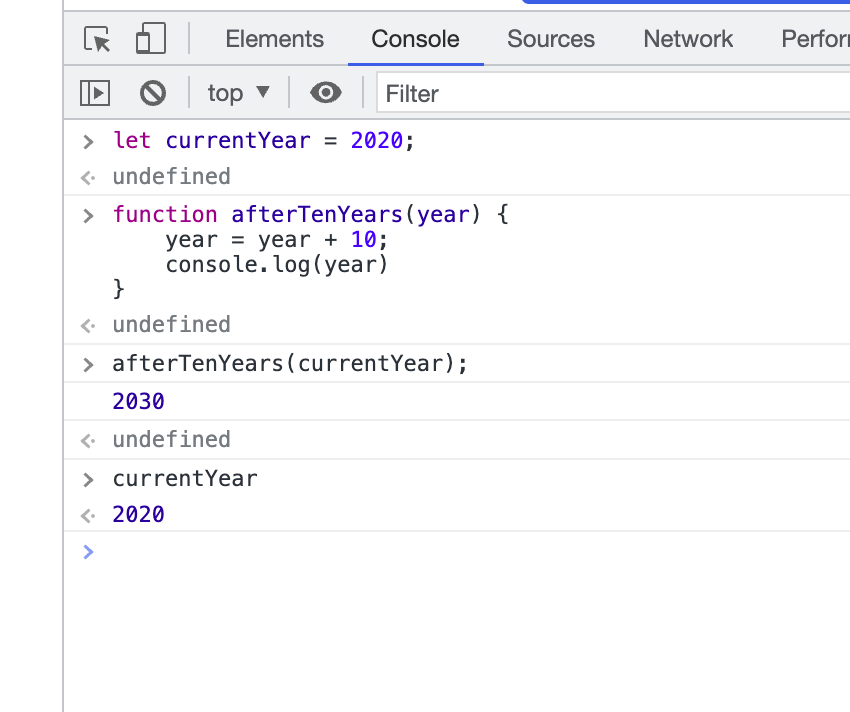
매개변수가 currentYear일 때
1) var 키워드 사용
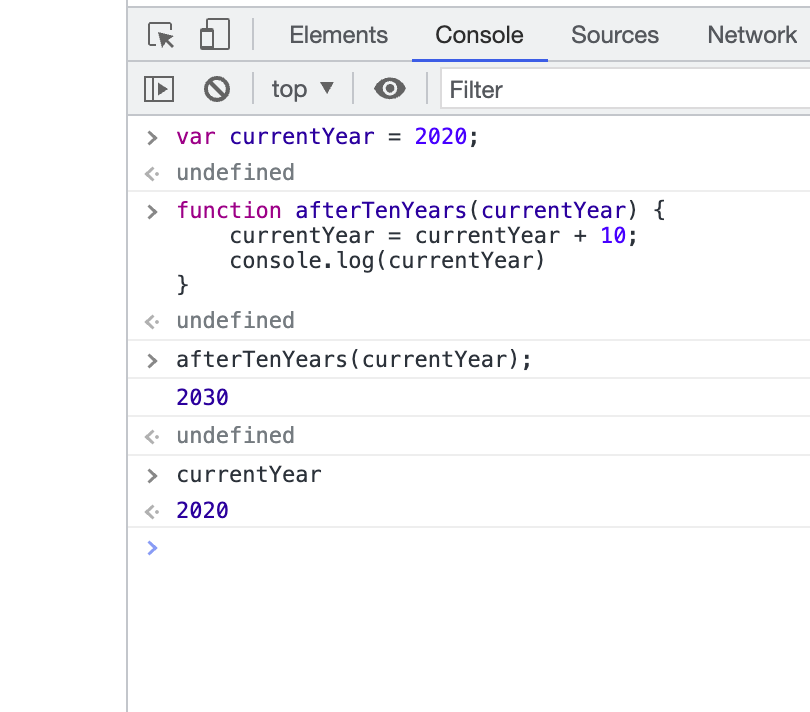
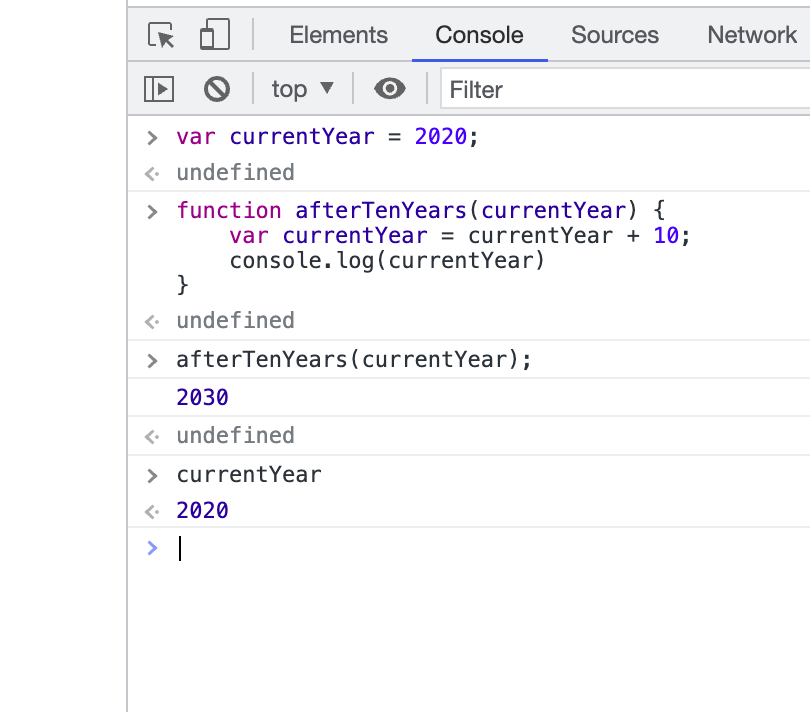
2) let 키워드 사용
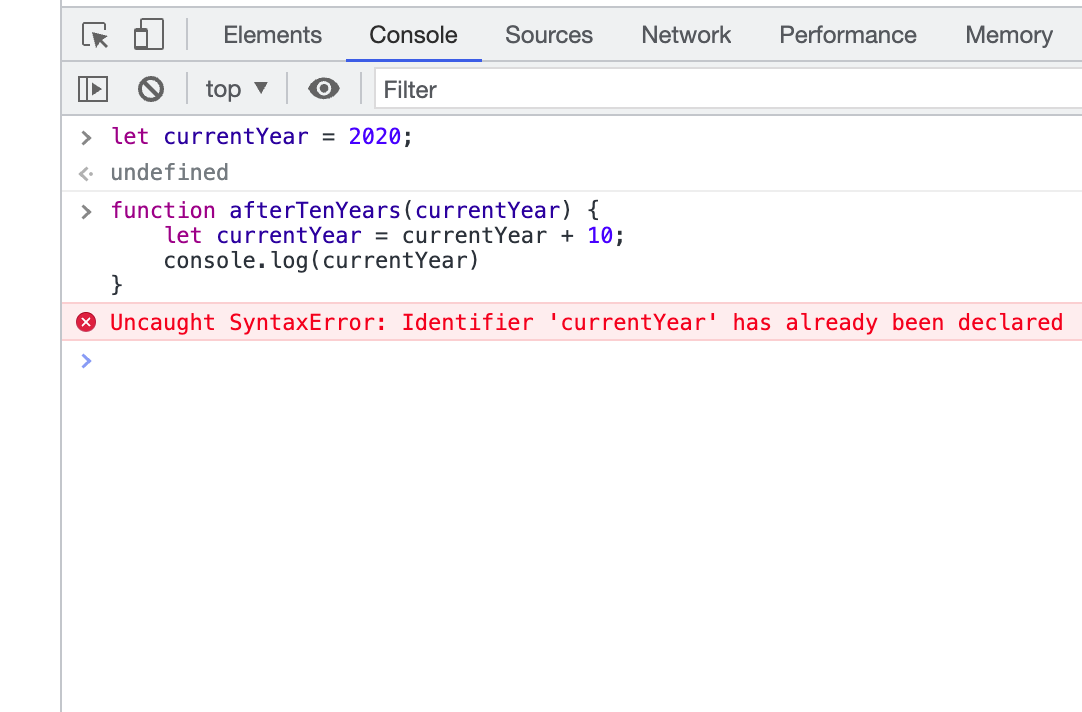
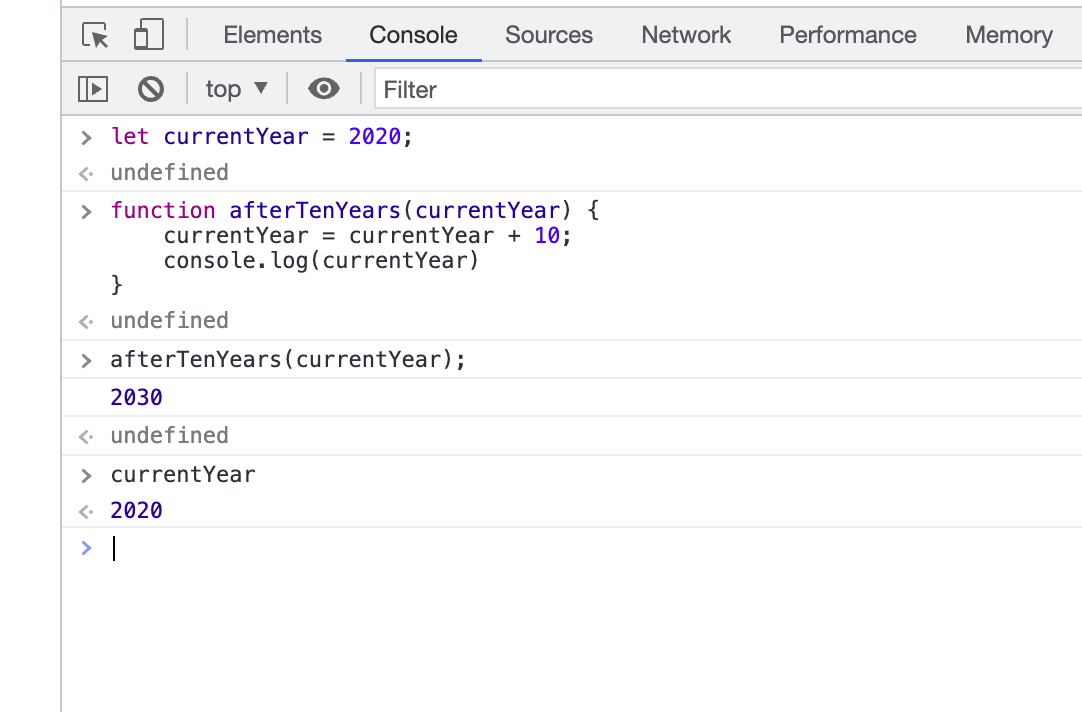
원시 자료형과 참조자료형 비교
자바스크립트에서 원시 자료형이 아닌 모든 것은 참조 자료형으로 배열([])과 객체({}), 함수(function(){})가 대표적이다.
const pi = 3.14
const arr = ["hello", "world", "code", "states"];
- 여기서 변수 pi에는 3.14라는 원시 자료형 '값'이 할당되고, arr에는 참조 자료형의 '주소'가 할당된다.
(영어 단어 reference 의미와 연결시켜보면 실제 데이터가 저장된 주소를 가리킨다(refer), 즉, 참조(reference)한다.)
원시 자료형은 immutable 하지만 참조 자료형은, 그렇지 않다.
배열에 요소를 추가 및 삭제하고, 객체에 속성을 추가 및 삭제할 수 있다.
이것 자체가, 참조 자료형은 이미 immutable하지 않다는 것을 보여주고 있다.
언제든 데이터가 늘어나고 줄며 동적으로 변하기 때문에 특별한 저장공간(heap)의 주소를 변수에 할당한다.
아래와 같이 코드가 작성되어 있다면...
let num = 123;
const msg = "hello";
let arr = [1, 2, 3];
const isOdd = true;
원시 자료형의 데이터가 저장되는 공간 (stack)
1 | num | 123
2 | msg | "hello"
3 | arr | heap의 12번부터 3개 // (실제 데이터가 저장되어 있는 주소)
4 |isOdd| true
=====================================
Object 자료형의 데이터가 저장되는 공간 (heap)
10 ||
11 ||
12 || 1
13 || 2
14 || 3
실제 자바스크립트는 변수를 위와 같이 저장할 것이다.
it('참조 자료형의 데이터는 동적(dynamic)으로 변합니다.', function () {
const arr = [1, 2, 3];
expect(arr.length).to.equal(3);
arr.push(4, 5, 6);
expect(arr.length).to.equal(6);
arr.pop();
expect(arr.length).to.equal(5);
const obj = {};
expect(Object.keys(obj).length).to.equal(0);
obj['name'] = 'codestates';
obj.quality = 'best';
obj.product = ['sw engineering', 'product manager', 'growth marketing', 'data science'];
expect(Object.keys(obj).length).to.equal(3);
delete obj.name;
expect(Object.keys(obj).length).to.equal(2);
});
it('참조 자료형을 변수에 할당할 경우, 데이터의 주소가 저장됩니다.', function () {
const overTwenty = ['hongsik', 'minchul', 'hoyong'];
let allowedToDrink = overTwenty;
overTwenty.push('san');
expect(allowedToDrink).to.deep.equal(['hongsik', 'minchul', 'hoyong', 'san']);
overTwenty[1] = 'chanyoung';
expect(allowedToDrink[1]).to.deep.equal('chanyoung');
// .deep.equal은 배열의 요소나 객체의 속성(내용물)이 서로 같은지 확인하는 matcher이다.
const ages = [22, 23, 27];
allowedToDrink = ages;
expect(allowedToDrink === ages).to.equal(true);
expect(allowedToDrink === [22, 23, 27]).to.equal(false);
const nums1 = [1, 2, 3];
const nums2 = [1, 2, 3];
expect(nums1 === nums2).to.equal(false);
const person = { //객체 안의 객체
son: {
age: 9,
},
};
const boy = person.son;
boy.age = 20;
expect(person.son.age).to.equal(20);
expect(person.son === boy).to.equal(true);
expect(person.son === { age: 9 }).to.equal(false);
expect(person.son === { age: 20 }).to.equal(false);
});
});
[] === [] 가 false인 이유
const nums1 = [1, 2, 3];
const nums2 = [1, 2, 3];
expect(nums1 === nums2).to.equal(false);
배열 nums1과 배열 num2에는 동일한 데이터 [1, 2, 3]이 들어있는 게 분명해 보이는데, 이 둘은 같지가 않다.
사실 변수 num1와 num2는 배열이 아니다. 참조 타입의 변수에는 (데이터에 대한) 주소만이 저장된다.
정확히 말해서 변수 num1은 데이터 [1, 2, 3]이 저장되어 있는 메모리 공간(heap)을 가리키는 주소를 담고 있다.
따라서 위의 코드는 각각 다음의 의미를 가지고 있다.
const nums1 = [1, 2, 3]; // [1, 2, 3]이 heap에 저장되고, 이 위치의 주소가 변수 num1에 저장된다.
const nums2 = [1, 2, 3]; // [1, 2, 3]이 heap에 저장되고, 이 위치의 주소가 변수 num2에 저장된다.
이제 heap에는 두 개의 [1, 2, 3]이 저장되어 있고, 각각에 대한 주소가 변수 num1, num2에 저장되어 있다.
이게 비효율적으로 보일수도 있다. 굳이 같은 데이터를 왜 한번 더 저장하는 지 이해하기란 쉽지 않다.
하지만 [1, 2, 3]이 아니라 상당히 큰 데이터(예. length가 100,000인 배열)를 가지고 다시 생각해 보자.
const nums1 = [10, 2, 71, ..., 987]; // 길이 100,000개인 배열
const nums2 = [10, 2, 71, ..., 987]; // 길이 100,000개인 배열
이 두 배열이 서로 같아서 두 번 저장할 필요가 없다고 말하려면, 일단 두 배열이 같은지 확인해야 한다.
이런 작업을 Object 자료형을 쓸 때마다 한다고 가정해보면, 이것이 얼마나 비효율적인지를 금방 알 수 있다.
정리
1) [1, 2, 3]; // [1, 2, 3]이라는 데이터가 heap에 저장되지만 변수 할당이 되지 않아 주소는 어디에도 저장되지 않는다.
2) const num1 = [1, 2, 3]; // // [1, 2, 3]이라는 데이터가 heap에 저장되고, 그 주소가 변수 num1에 저장된다.
3) const num2 = [1, 2, 3]; // // [1, 2, 3]이라는 데이터가 heap에 저장되고, 그 주소가 변수 num2에 저장된다.
1), 2), 3)에서 말하는 주소는 전부 다른 주소이다.
'FE > JavaScript' 카테고리의 다른 글
| [JS] test를 통한 spread syntax 개념 익히기 _Koans (0) | 2023.03.07 |
|---|---|
| [JS] test를 통한 구조 분해 할당 개념 익히기 _Koans (0) | 2023.03.06 |
| [JS] test를 통한 object 개념 익히기 _Koans (0) | 2023.03.06 |
| [JS] this (0) | 2023.03.06 |
| [JS] test를 통한 array 개념 익히기 _Koans (0) | 2023.03.06 |