React의 가상 DOM 비교 알고리즘
React가 기존 가상 DOM과 변경된 새로운 가상 DOM을 비교할 때, React 입장에서는 변경된 새로운 가상 DOM 트리에 부합하도록 기존의 UI를 효율적으로 갱신하는 방법을 알아낼 필요가 있었다.
즉 하나의 트리를 다른 트리로 변형을 시키는 가장 작은 조작 방식을 알아내야만 했다.
- 알아낸 조작 방식 알고리즘은 O(n^3)의 복잡도를 가지고 있었다.
- O(n^3) 복잡도는 입력 크기에 대해 세제곱 비례로 증가하는 복잡도를 의미한다.
- 알고리즘의 성능을 분석하기 위해 복잡도를 계산하는 것은 중요한 과정이다.
- 이를 통해 알고리즘의 효율성을 평가하고, 큰 입력에 대해 얼마나 잘 처리할 수 있는지 예측할 수 있다.
- 일반적으로 좋은 알고리즘은 작은 복잡도를 가지며, 큰 입력에도 효율적으로 처리할 수 있는 방식을 제공한다.
React의 가상 DOM 비교 알고리즘은 실제 DOM에 적용되는 변경 사항을 최소화하기 위해
두 개의 가상 DOM 트리를 비교하는 과정에서 수행된다.
- 이 과정에서 가장 작은 조작 방식을 찾아내는 것이 중요하다.
- React의 가상 DOM 비교 알고리즘은 두 가상 DOM 트리의 각 노드를 비교하고, 변경 사항을 식별하기 위해 노드 유형, 속성, 자식 요소 등을 고려한다.
- 이를 통해 변경되거나 추가된 요소, 제거된 요소, 변경된 속성 등을 식별하고, 최종적으로 변경 사항을 실제 DOM에 적용한다.
복잡도가 O(n^3)로 나타난 이유는 비교 과정에서의 반복 및 중첩된 반복문이 발생하기 때문이다.
- 예를 들어, 두 가상 DOM 트리의 각 노드를 비교하기 위해 이중 반복문을 사용한다.
- 이 때 각 노드의 조작을 확인하기 위해 추가적인 반복문이 필요할 수 있다.
- 이렇게 반복문이 중첩되고, 그 안에서 노드 조작을 확인하는 작업이 이루어지므로 복잡도가 O(n^3)가 되는 것이다.
- 예를 들어, 하나의 트리를 다른 트리로 변형하기 위해 모든 가능한 조작을 시도해야 한다고 가정해보자.
- 이 때 트리에 있는 노드의 개수를 n이라고 하면, 첫 번째 반복문은 n개의 노드를 선택하기 위해 n번 실행된다.
- 두 번째 반복문은 노드의 연결 관계를 선택하기 위해 n번 실행된다.
- 마지막 반복문은 각 연결 관계마다 가능한 변형을 시도하기 위해 다시 n번 실행 된다.
- 따라서 전체적으로 O(n^3)의 복잡도를 가지게 된다.
만약 이 알고리즘을 그대로 React에 적용한다면 1000개의 엘리먼트를 실제 화면에 표시하기 위해 10억(1000^3)번의 비효율적이고 비싼 비교 연산을 해야만 한다.
- React는 두 가지의 가정을 가지고 시간 복잡도 O(n)의 새로운 휴리스틱 알고리즘(Heuristic Algorithm)을 구현해 낸다.
- 두 가지 가정은 이것이다.
- 각기 서로 다른 두 요소는 다른 트리를 구축할 것이다.
- 개발자가 제공하는 key 프로퍼티를 가지고, 여러 번 렌더링을 거쳐도 변경되지 말아야 하는 자식 요소가 무엇인지 알아낼 수 있을 것이다.
실제 이 두 가정은 거의 모든 실제 사용 사례에 들어맞게 된다. 여기서 React는 비교 알고리즘(Diffing Algorithm)을 사용한다.
React가 DOM 트리를 탐색하는 방법
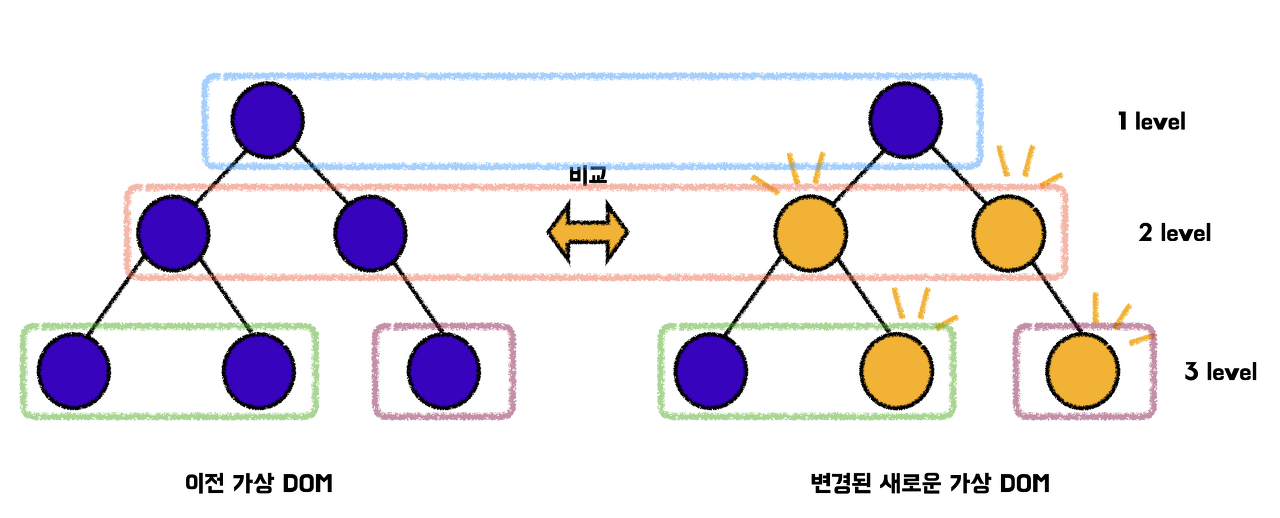
React는 기존의 가상 DOM 트리와 새롭게 변경된 가상 DOM 트리를 비교할 때, 트리의 레벨 순서대로 순회하는 방식으로 탐색한다.
- 즉 같은 레벨(위치)끼리 비교한다는 뜻이다.
- 이는 너비 우선 탐색(BFS)의 일종이라고 볼 수 있다.
React의 DOM 트리 순회 방식
React는 이런 식으로 동일 선상에 있는 노드를 파악한 뒤 다음 자식 세대의 노드를 순차적으로 파악해 나간다.
다른 타입의 DOM 엘리먼트인 경우
그런데 DOM 트리는 각 HTML 태그마다 각각의 규칙이 있어 그 아래 들어가는 자식 태그가 한정적이라는 특징이 있다.
- (예를 들어 <ul> 태그 밑에는 <li> 태그만 와야 한다던가, <p> 태그 안에 <p> 태그를 또 쓰지 못하는 것)
- 자식 태그의 부모 태그 또한 정해져 있다는 특징이 있다.
- 따라서 부모 태그가 달라진다면 React는 이전 트리를 버리고 새로운 트리를 구축해 버린다.
<div>
<Counter />
</div>
//부모 태그가 div에서 span으로 바뀐다.
<span>
<Counter />
</span>
이렇게 부모 태그가 바뀌어버리면, React는 기존의 트리를 버리고 새로운 트리를 구축하기 때문에 이전의 DOM 노드들은 전부 파괴된다.
- 부모 노드였던 <div>가 <span>으로 바뀌어버리면 자식 노드인 <Counter />는 완전히 해제된다.
- 즉 이전 <div> 태그 속 <Counter />는 파괴되고 <span> 태그 속 새로운 <Counter />가 다시 실행된다.
- 새로운 컴포넌트가 실행되면서 기존의 컴포넌트는 완전히 해제(Unmount)되어버리기 때문에 <Counter />가 갖고 있던 기존의 state 또한 파괴된다.
같은 타입의 DOM 엘리먼트인 경우
반대로 타입이 바뀌지 않는다면 React는 최대한 렌더링을 하지 않는 방향으로 최소한의 변경 사항만 업데이트한다.
- 이것이 가능한 이유는 앞서 React가 실제 DOM이 아닌 가상 DOM을 사용해 조작하기 때문이다.
- 업데이트할 내용이 생기면 virtual DOM 내부의 프로퍼티만 수정한 뒤, 모든 노드에 걸친 업데이트가 끝나면 그때 단 한번 실제 DOM으로의 렌더링을 시도한다.
<div className="before" title="stuff" />
// 기존의 엘리먼트가 태그는 바뀌지 않은 채 className만 바뀌었다.
<div className="after" title="stuff" />
React는 두 요소를 비교했을 때 className만 수정되고 있다는 것을 알게 된다.
className before와 after는 각자 이런 스타일을 갖고 있다.
//className이 before인 컴포넌트
<div style={{color: 'red', fontWeight: 'bold"}} title="stuff" />
//className이 after인 컴포넌트
<div style={{color: 'green', fontWeight: 'bold"}} title="stuff" />
두 엘리먼트를 비교했을 때 React는 정확히 color 스타일만 바뀌고 있음을 눈치챈다.
- 따라서 React는 color 스타일만 수정하고 fontWeight 및 다른 요소는 수정하지 않는다.
- 이렇게 하나의 DOM 노드를 처리한 뒤 React는 뒤이어서 해당 노드들 밑의 자식들을 순차적으로 동시에 순회하면서 차이가 발견될 때마다 변경한다.
- 이를 재귀적으로 처리한다고 표현한다.
자식 엘리먼트의 재귀적 처리
예를 들면 이렇게 자식 엘리먼트가 변경이 된다고 가정하겠다.
- React는 기존 <ul>과 새로운 <ul>을 비교할 때 자식 노드를 순차적으로 위에서부터 아래로 비교하면서 바뀐 점을 찾는다.
- 그렇기 때문에 예상대로 React는 첫 번째 자식 노드들과 두 번째 자식 노드들이 일치하는 걸 확인한 뒤 세 번째 자식 노드를 추가한다.
<ul>
<li>first</li>
<li>second</li>
</ul>
// 자식 엘리먼트의 끝에 새로운 자식 엘리먼트를 추가했다.
<ul>
<li>first</li>
<li>second</li>
<li>third</li>
</ul>
이렇게 React는 위에서 아래로 순차적으로 비교하기 때문에, 이 동작 방식에 대해 고민하지 않고 리스트의 처음에 엘리먼트를 삽입하게 되면 이전의 코드에 비해 훨씬 나쁜 성능을 내게 된다.
<ul>
<li> Duke </li>
<li> Villanova </li>
</ul>
<!--자식 엘리먼트를 처음에 추가한다.-->
<ul>
<li> Connecticut </li>
<li> Duke </li>
<li> Villanova </li>
</ul>
이렇게 구현하게 되면 React는 우리의 기대대로 최소한으로 동작하지 못하게 된다.
- React는 원래의 동작하던 방식대로 처음의 노드들을 비교하게 된다.
- 처음의 자식 노드를 비교할 때, <li> Duke </li>와 <li> Connecticut </li>으로 자식 노드가 서로 다르다고 인지하게 된 React는 리스트 전체가 바뀌었다고 받아들인다.
- <li> Duke </li>와 <li> Villanova </li>는 그대로이기 때문에 두 자식 노드는 유지시켜도 된다는 것을 깨닫지 못하고 전부 버리고 새롭게 렌더링 해버린다.
- 이는 굉장히 비효율적인 동작 방식이다.
- 그래서 React는 이 문제를 해결하기 위해 key라는 속성을 지원한다.
- 이는 효율적으로 가상 DOM을 조작할 수 있도록 한다.
- 만일 개발할 당시 key라는 속성을 사용하지 않으면 React에서 key값을 달라고 경고문을 띄우는 것도 이 때문이다.
- key값이 없는 노드는 비효율적으로 동작할 수 있기 때문이다.
키(key)
만약 자식 노드들이 이 key를 갖고 있다면, React는 그 key를 이용해 기존 트리의 자식과 새로운 트리의 자식이 일치하는지 아닌지 확인할 수 있다.
- 아래 코드를 보면 React는 key 속성을 통해 ‘2014’라는 자식 엘리먼트가 새롭게 생겼고, ‘2015’, ‘2016’ 키를 가진 엘리먼트는 그저 위치만 이동했다는 걸 알게 된다.
- 따라서 React는 기존의 동작 방식대로 다른 자식 엘리먼트는 변경하지 않고 추가된 엘리먼트만 변경한다.
- 이 key 속성에는 보통 데이터 베이스 상의 유니크한 값(ex. Id)을 부여해 주면 된다.
- 키는 전역적으로 유일할 필요는 없고, 형제 엘리먼트 사이에서만 유일하면 된다.
<ul>
<li key="2015">Duke</li>
<li key="2016">Villanova</li>
</ul>
<!--key가 2014인 자식 엘리먼트를 처음에 추가한다.-->
<ul>
<li key="2014">Connecticut</li>
<li key="2015">Duke</li>
<li key="2016">Villanova</li>
</ul>
만약 이런 유니크한 값이 없다면 최후의 수단으로 배열의 인덱스를 key로 사용할 수 있다.
- 이는 심각한 문제를 초래할 수 있는데 아래 예시를 보면 바로 이해가 될 것이다.
배열의 인덱스를 key로 사용할 때의 문제 예시
배열의 인덱스를 key로 선택했을 경우에 다만 배열이 다르게 정렬될 경우가 생긴다면 비효율적으로 동작하게 된다.
- 왜냐하면 배열이 다르게 정렬되어도 인덱스는 그대로 유지되기 때문이다.
- 인덱스는 그대로지만 그 요소가 바뀌어버린다면 React는 배열의 전체가 바뀌었다고 받아들일 것이고, 기존의 DOM 트리를 버리고 새로운 DOM 트리를 구축해 버린다.
예를 들어, 리스트에서 항목을 삭제하는 경우를 생각해 보자.
- 기존의 리스트에서 항목을 삭제하면, 해당 항목 이후의 모든 항목의 인덱스가 변경된다.
- 이로 인해 React에서는 가상 DOM 비교 과정에서 변경된 인덱스를 감지하지 못하고 모든 항목을 변경된 것으로 판단할 수 있다.
- 결과적으로 삭제된 항목에 대한 모든 컴포넌트를 다시 렌더링하게 되어 성능 저하가 발생할 수 있다.
문제의 상황을 코드로 나타내보자면 아래와 같다.
// 초기 상태의 리스트
const list = ['A', 'B', 'C', 'D', 'E'];
// 삭제 후의 리스트
const modifiedList = ['A', 'C', 'D', 'E'];
// React 컴포넌트에서 사용하는 코드
return modifiedList.map((item, index) => (
<div key={index}>{item}</div>
));
위 예시에서, 원래 'B'라는 항목이 삭제되었고, 변경된 리스트를 렌더링할 때 배열의 인덱스를 key로 사용하였다.
- 그러나 'C', 'D', 'E' 항목들의 인덱스가 변경되었기 때문에 React는 모든 항목이 변경된 것으로 인식한다.
- 결과적으로 'C', 'D', 'E' 항목들의 컴포넌트들이 다시 렌더링되어야 하므로 성능 저하가 발생할 수 있다.
이와 달리, 유니크한 값을 key로 사용했다면, 삭제된 항목에 대한 컴포넌트만 렌더링되었을 것이다.
- 이는 변경된 부분에 대해서만 업데이트를 수행하여 성능을 향상시킬 수 있다.
- 따라서, 배열의 인덱스를 key로 사용하는 것은 유니크한 값이 없을 때의 "최후의 수단"으로 사용될 수 있지만, 배열의 순서가 변경될 가능성이 있는 경우에는 효율적이지 않을 수 있다.
- 가능하다면 고유한 ID나 다른 유니크한 값을 key로 사용하는 것이 좋다.
'FE > React' 카테고리의 다른 글
| React의 렌더링 최적화를 도와주는 useMemo (0) | 2023.05.19 |
|---|---|
| React의 Hook의 개념과 사용 규칙 (0) | 2023.05.19 |
| [React] Virtual DOM (0) | 2023.05.19 |
| [JS] useEffect 용례 (0) | 2023.05.04 |
| 쇼핑몰 앱에서 Redux를 이용한 상태 관리 (2) (0) | 2023.04.26 |